MIT6.828 Homework Shell
1. 下载sh.c文件
2. 实现ls
首先是一些前备知识
- access : 检查调用进程是否可以对指定的文件执行某种操作。
// pathname :文件路径
// mode : 操作模式
int access(const char * pathname, int modeR_OK 测试读许可权
W_OK 测试写许可权
X_OK 测试执行许可权
F_OK 测试文件是否存在
- int execv(const char path, char const argv[]);
第一个表示需要运行的程序的路径,比如说ls, wc,echo等等。
第二个参数表示程序所需呀的参数,比如说ls /,打印根目录下的所有的目录。
xv6book提到了说大多数的程序忽略了第一个参数,因为它通常是程序的名字。也就是说,agrv[0]是程序名字,agrv是参数。
- strcat : 将两个“字符串”连接起来,返回到第一个参数
case ' ':
ecmd = (struct execcmd*)cmd;
if(ecmd->argv[0] == 0)
_exit(0);
// fprintf(stderr, "exec not implemented\n");
// Your code here ...
char path[20] = "/bin/";
if(access(ecmd->argv[0],F_OK)==0){
execv(ecmd->argv[0],ecmd->argv);
}
else{
strcat(path,ecmd->argv[0]);
if(access(path,F_OK)==0) execv(path,ecmd->argv);
else{
fprintf(stderr, "exec not implemented\n");
}
}
break;注:这里为什么要连接一个path数组呢,是因为路径问题,ls存在于/usr/bin/ls,因此我们必须得把路径搞完整。
实验结果:

3. I/O重定向
-
文件描述符的分配
0 -> 标准输入
1 -> 标准输出
2 -> 错误输出并且每次分配时,总是从未分配的最小值开始
因此,我们实现I0重定向的思路就出来了。首先应该先关闭对应的文件描述符,然后再打开需要重定向的文件即可。
case '>':
// it's not necessary to write. case '>' and '<' can be merge to one.
case '<':
rcmd = (struct redircmd*)cmd;
// close standerd input/ output
close(rcmd->fd);
if (open(rcmd->file, rcmd->mode, S_IWUSR|S_IRUSR) < 0) {
fprintf(stderr, "file:%s no exist\n",rcmd->file);
exit(0);
}
// why don't we need to change type to ' '?
rcmd->type = ' ';
runcmd(rcmd->cmd);
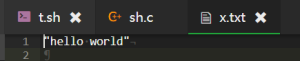
// rcmd->cmd 代表的就是重定向符号前的命令,例如 echo "hello world"
break;实验结果:

4.管道通信(pipe)
int pipe(int p[])
建立一个缓冲区,并把缓冲区通过 fd 形式给程序调用。它将 p[0] 修改为缓冲区的读取端, p[1] 修改为缓冲区的写入端。int dup(int old_fd)
产生并返回与old_fd指向同一文件的fd。产生的 fd 总是空闲的最小 fd。
要实现ls | sort | uniq | wc这类命令,重点在于如何使得上一个进程/上一条命令的输出变成下一个进程的输入,这就涉及到进程间通信的相关知识,进程间通信最简单最笨拙的方式就是通过文件系统来实现进程间的通讯,但这种方式效率太低,速度太慢(因为要对硬盘直接进行操作),还有一种方式是在OS内核中开辟出一块空间,以供进程通信,管道是一种利用文件系统接口,在OS内部实现的一种进程通信方式,具体解释和样例见xv6讲义第13页。
其实管道命令可以拆分为几个基础命令,这样比较易于理解。比如说
"echo hello world | wc " 效果等同于 "echo hello world " + "wc"
所以管道的一个核心要点,就是上面的红字,前一个的输出变成下一个的输入
case '|':
pipe(p);
// pipe 0 read 1 write
pcmd = (struct pipecmd*)cmd;
if (fork1() == 0) {
// left pipe
// standard output is redirected to write end of pipe
close(1);
dup(p[1]);
close(p[0]);
close(p[1]);
runcmd(pcmd->left);
}
wait(&r);
if (fork1() == 0) {
// standard input is redirected to read end of pipe
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
runcmd(pcmd->right);
}
close(p[0]);
close(p[1]);
wait(&r);
break;理解这段程序时,带着几个问题去读
- 本段程序一共有多少进程?
- 每个if语句里close+dup的命令组合在干什么?
- 为什么最后还要close(p[0]) close(p[1])
我先解答一下进程数量的问题,这是理解这个问题的基础。第一个进程肯定是调用fork1的父进程,然后呢,子进程1就出现了,父进程执行到wait,等啊等,等到子进程1结束。随后它又fork了另一个子进程,ok,答案是三个。
引用一下B站一个THU操作系统课程的一张图,Shell就是我们的父进程,他创建了ls和more两个子进程,两个子进程共享父进程拥有的资源,就是中间圆柱体的管道。

在剖析这部分东西时,我颅内训练了许久,但是还是觉得一团乱麻。当我尝试自己画个简略的过程图,我发现我就懂了。动手是个好习惯。

父进程执行pipe,在内存中开辟了一段空间作为管道,并且返回读写的文件描述符,分别是p[0]和p[1].
接着执行fork1,进入if语句的就是我们的子进程。
close(1) :代表把他的输出文件描述符关闭了
dup[p[1]] : 然后把fd[1]绑定到管道的写端(相当于图上绿色的箭头)
接下来的操作是close p[0]p[1],理解这两句话,只要明白父进程和子进程各自有自己的资源拷贝
我们在这里可以把管道当成一个全局变量,父进程有p[0]p[1],子进程也有,指的也是指到管道上。可以仔细看看图上,我把子进程那里的p加上下标来加以区分。但是呢,我们在代码里可不能写close(p1[0]),不能乱来,加下标只是用于理解,实际上人家子线程确确实实有两个变量p[0]p[1],只是是拷贝他爹的东西。
然后就愉快地执行左边的命令了 runcmd(pcmd->left) ,父进程在外面等子进程1结束。
接着再次创建子进程2,原理和上面说的一样了。
来到我们最后一个问题,为什么在子线程2结束前,我们要进行close(p[0]) close(p[1])操作呢?
通过刚刚的熏陶,我们应该要清楚这里关闭的是父进程的两个p。
xv6book里面有这么一段话,我把原文截下来。
If no data is available, a read on a pipe waits for either data to be written or all file descriptors referring to the write end to be closed; in the latter case, read will return 0, just as if the end of a data file had been reached. The fact that read blocks until it is impossible for new data to arrive is one reason that it’s important for the child to close the write end of the pipe before executing wc above: if one of wc’s file descriptors referred to the write end of the pipe, wc would never see end-of-file.
大意是,如果read端没有东西读了,它会等写端的引用计数为0之后,才会结束,否则就是阻塞,无法结束进程。
如果我们的父进程不关闭掉p[0]p[1],那么管道的引用计数一直会不为0,子进程2读也读不出来数据,因为读完了,停也停不了,引用计数还有呢。
至此,管道通信的解析结束了,下面看一下实验结果:

文章的最后再补充一点管道的知识:
管道通信必须满足三个条件:
一、互斥:读写进程必须互斥地访问管道
二、同步:读进程必须等写进程把管道写满再被唤醒
三、必须感知到对方的存在,管道存在一对一,也存在多对一的关系管道的缺点:
一、只能实现字节流,不能结构化数据
二、进程之间需要父子关系